일전에 들은 교육 내용을 정리하고자 한다.
통계 관련해서는 아는바가 없었는데, 생각보다 많은 내용을 배운 것 같다.
커리큘럼을 그대로 따라가기보다는... 내가 느낀바를 그대로 따라가면서 적어보자.
1. Pandas의 describe기능, 기초 통계량
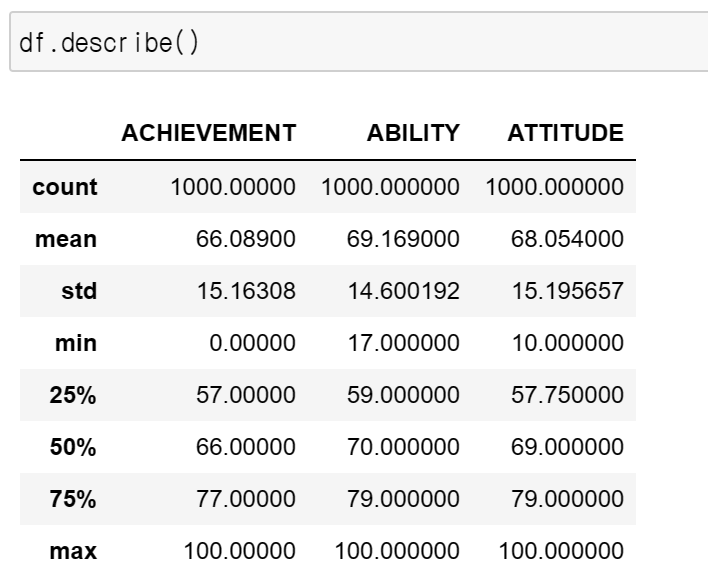
나는 몰랐는데, describe하면 이런 여러가지 것들이 찍힌다. 이걸 기초통계량이라고 한다.
기초통계량은 각각 이렇다.
- count : 말그대로 data의 수
- mean : 평균
- std : 표준편차
- min ~ max : 최소부터 최대까지 각각 사분위수의 값
2. Numpy와 Pandas, Series와 Data frame
Series와 Dataframe의 차이라 하면, 당연히 자료형이다.
dtype으로 출력해보는게 가장 원론적 방법이겠으나 좀 더 간편한 방법이라면 jupyter 기준으로 직접 출력해보면 된다.
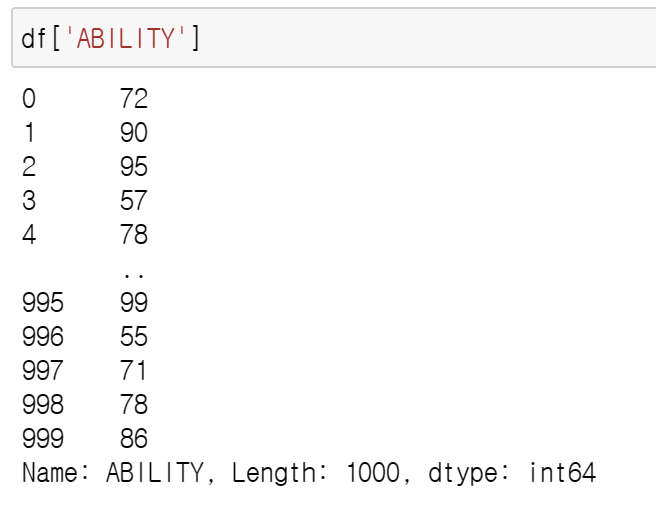

위의 예시와 같이 특정 column만 List처럼 사용할 때 대괄호를 한 번 쓰면 series, 두번 쓰면 똑같은 dataframe으로 반환해서 사용하게 된다.
이걸 굳이 구분하는 이유는 연산할때 series만 되는 경우도 있기 때문인데, 사실 Dataframe class의 내장함수를 사용할때가 아니라면 거의 다 series로 바꿔서 사용해야 한다고 생각하면 될 것 같다.
예를들어 동일하게 Average를 가져올때도 내장함수 mean을 사용할 수 있지만 Numpy 등의 변수로 넣어줄때는 series로 넣어줘야 한다.

3. 검정통계량과 Data 분석 방법
Data 분석의 목적이라면 어떤 data로 하여금 새로운 가설의 진위여부를 가려내는 것이라고 할 수 있다.
이 때 쓰이는 가설은 귀무가설(H0)과 대립가설(H1)로 나눌 수 있다.
위키피디아의 정의를 인용하면 아래와 같다.
- 귀무가설 : 통계학에서 처음부터 버릴 것을 예상하는 가설
- 대립가설 : 귀무가설이 거짓이라면 대안적으로 참이 되는 가설
귀무가설은 일반적으로 기존에 존재하던 가설을 의미하며, 우리가 주장하고자 하는 새로운 가설은 대립가설이 된다.
따라서 어떤 Data를 분석하여 기존의 귀무가설이 거짓이며 우리가 주장하려는 대립가설이 참이라고 주장하는 것이 Data 분석의 목표가 되겠다. (당연히 귀무가설이 참이라고 결론날수도있다.)
이런 가설 검정 프로세스는 3가지 절차로 이루어지는데,
- 가설을 세운다.
- 검정 통계량을 구한다.
- P-value를 분석하여 결론을 내린다.
이런 절차로 가설검정을 하기 위해 위와 같이 검정통계량을 구하는 것이다.
대부분의 통계방법은 데이터가 정규분포를 따를 때, 즉 정규성검정을 통과해야 하는데
이런 정규성검정의 대표적 방법인 샤피로 윌크 검정 방법을 예시로 들 수 있다.

검정통계량의 의미까진 자세히 몰라도 괜찮다...
일단 shapiro-wilk test는 아래와 같은 가설의 검정이다.
- H0 : 정규분포를 따른다.
- H1 : 정규분포를 따르지 않는다.
Python의 Scipy module에서는 다양한 test를 제공하는데, 그중에는 shapiro-wilk test도 있어서 그대로 사용하면 된다.

Shapiro-wilk Test의 예시로 저런 결과가 나왔는데, 우리가 주목할것은 최종 결론인 P-value.
검정통계량을 통한 분석까지는 Scipy에서 알아서 제공해주니 사용하고 나면 이런 결론을 내릴 수 있다.
- P-value가 높은 전자는 H0가 참(정규분포를 따름)
- P-value가 낮은 후자는 H0가 거짓(정규분포를 따르지 않음)
4. P-Value?
사실 교육을 들으면서 가장 낯선 말을 뽑으라면 나에게는 P-value였다.
그닥 어려운 개념은 아닌듯한데 통계를 처음 접하다보니 아예 처음 듣는 말이라서...
아주 쉽게 요약하자면, P-Value는 H0가 얼마나 잘 맞을지에 대한 척도라고 보면 될 것 같다.
즉 H1이 참이기위해선 P-value가 낮아야한다.
P-value의 엄밀한 뜻은 귀무가설H0가 참이라고 했을 때 표본 Data가 수집될 확률이다.
내가 가지고있는 표본 data가 어떤 가설로부터 수집됐는지에 대한 확률이니, 당연히 높을수록 귀무가설이 참이라는 의미라는것.
일반적으로 P-value는 0.05를 기준으로 둔다.
무슨 의미냐면, P-value가 0.05보다 높을경우 H0 / 0.05보다 낮을경우 H1가 참이 된다는 의미다.
이 때 0.05를 유의수준이라고 하는데, P-value의 맹점은 Data 수가 늘어날수록 점점 더 낮은 값이 나온다는 점이다.
즉 유의수준은 내가 보는 Data와 상황에 따라 조정될 필요가 있으며, 그렇지 않으면 항상 H1이 참이라는 이상한 결론이 나올 수 있다.
(특히 실무에서는 P-value가 거의 10^-30까지 나온다고 하더라...)
'글 > 코딩' 카테고리의 다른 글
| [키움 API] 총 자산 불러오기 (0) | 2023.09.06 |
|---|---|
| 백준 알고리즘 문제 풀이 11659 : 구간 합 구하기 4 (0) | 2023.07.26 |
| 백준 알고리즘 문제 풀이 1764 : 듣보잡 (0) | 2023.07.05 |
| [python][자동매매] 강의가 끝나고, 머릿속 정리 3. 계좌정보 불러오기 + Tr Data 불러오기 (0) | 2023.06.01 |
| [python][자동매매] 강의가 끝나고, 머릿속 정리 2. Login (0) | 2023.05.31 |

